Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems.
Everyone seems to hate regular expressions. I hated them for years. When I needed to get a phone number out of a string, or an attribute of an HTML element, I’d Google it and copy and paste the first StackOverflow results together into my language of choice. In a university level compilers course, I learned how to appreciate regular expressions for the beautiful thing they are. While I am by no means an expert, I have a solid appreciation for the problem they are designed to solve. In this article I will try to show this to you by starting not from regular expressions, but formal languages. So let’s start from the other side.
Formal languages consist of words whose letters are taken from an alphabet and are formed according to a specific set of rules called a grammar. Grammars are a series of transformations. They play nicely into tree structures since at each point you could choose a substitution if there is one. Essentially, the rules are defined by mapping a symbol to a construct like so:
$$S \rightarrow\ a S \vert bS\vert c$$
In this example, I use an alphabet of {a, b, c} and the entire grammar is expressed in one rule. The rule maps the symbol S to three possible choices (the pipe operator is a familiar or). In this language, the letters a or b can be zero to infinitely repeated but must end with a c. The symbol S on the right hand side can be replaced by anything on the right side of S, meaning this structure is recursive. If you start with an empty string and you apply rule S, you can choose between three things, aS, bS, or c. Let’s say you take aS, now you have another S, so you choose bS, so now you have abS, and for the new S you choose aS again, you get abaS, and for your new S you choose c, resulting in abac. Each time you replace a symbol which references another rule, with its corresponding right handle value, you are consuming the symbol. So for example, abac is a valid word under this language, but cb is not.
Let’s keep our basic language in mind. Let me introduce a new one. I will use the same alphabet, but introduce a new set of rules.
$$A \rightarrow\ B a \vert B b | a \\ B \rightarrow Aa \vert c$$
In this grammar we have two rules. When there is more than one rule, we must choose one to start with and always use the same one. In this example I choose A. A can go to Ba, Bb, or a which means a is a valid word in this language, and so is ca or aaa but not caa because there is no way we can make that string from these rules (try it!).
Formal Language
The languages I presented above are formal. This is because they fulfill 4 criterion:
- By definition, the empty language and empty string are regular.
- For each letter in the alphabet of the language, e.g. a, if you were to make a language consisting of only
$$S \rightarrow\ a$$
then it would be regular, by definition.
- If A and B are regular languages, then the union of A and B is regular. This means if we make a new language, where S maps to either A or B as defined by the union operator | which is equivalent to an OR.
$$S \rightarrow\ A \vert B \\ A\rightarrow\ a \\ B\rightarrow\ b$$
Figure 2
then this is also regular. The concatenation is also regular, so A ∙ B is simply denoted by putting two symbols next to each other.
$$S \rightarrow\ AB | BA$$
is also regular.
Are things starting to look familiar? By definition, any regular language that we describe in a syntax as in figure 2 has precisely one equivalent regular expression. The core take away is that a regular expression is simply a compressed representation of such a simple mapping.
Foray into Automata
I briefly want to show you how a computer takes an input string like aaaa and checks whether it matches a given grammar, such as the grammar in figure 1. At an abstract level, these things are best reasoned with by using automaton. An automaton is a graph which consists of nodes, and each edge (path) between nodes is a decision that consumes one input character if it matches. Each edge consumes one character, and all characters are fed into the automaton, starting with the starting node and hopefully ending on a goal node (accepting state). If all characters are consumed and the current node is not an accepting state, the input string is not a valid word in the language the automaton represents. In other words, the string doesn’t match.
Without going in to how they are constructed, every regular expression can be represented as a Non-deterministic Finite Automaton and a Deterministic Finite Automaton, which are two similar ways to model a regular language matcher. For simplicity’s sake, I present the DFA for the grammar (ε is just an empty character):
$$S \rightarrow\ a S \vert bS\vert \epsilon$$
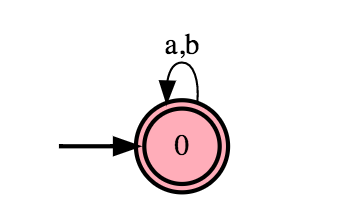
This is as simple as it gets, since anything that goes into the graph from the left that is an empty string, an a, or a b and is immediately in the goal state (notice the doubled contours of the node). Then, there is only one way out the node, that is via the edge for a or b, but if you take it, you end up in the goal node. So imagine the string abab. It comes in, the first letter a is in the goal node, so it is popped off the beginning. the next character b goes via the a,b edge back to the same node, and it is still a goal node so it matches. The same spiel for a, and again for b. Simple. Now imagine a string abc. a goes in, goal state, pop, b continues off from where a was popped, it follows the edge back to itself, but then c comes along. It has no where to go. The string to be matched has been reduced from abc to bc, and now to c, but it can’t go anywhere. Since the string is not empty, we have to terminate and our expression failed to match.
The following example is slightly more complicated and represents the following grammar:
$$S \rightarrow\ a X c \\ X \rightarrow a \vert b \vert c$$
This grammar accepts any string that starts with an a, has one a, b, or c in between, ending in a c. So let’s imagine we have a string abc, and we want to check if it matches the grammar above. The computer turns the grammar into an automaton like so:
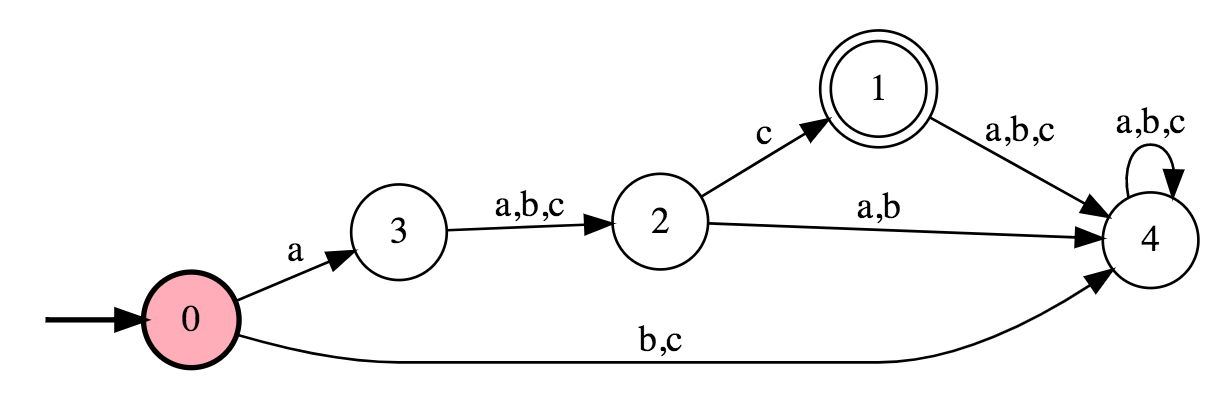
Our string abc is loaded onto a stack, the first character on the left goes into the DFA: the computer is in state 0, since we have an a and an edge labeled a, it moves to state 3. This state transition consumes the a and we are left with bc on our stack. Next, the computer can choose between a, b, or c to progress. We have a b on the top of the stack, so the computer moves to state 2, also consuming our b. Now we have only the c on our stack, and the computer takes the edge to state 1. Since state 1 is a goal state (denoted by the double contour), and our stack is now empty (remember the c got consumed by the transition), the computer successfully matched this string to the grammar. Try it with a string that doesn’t work, such as abbc. You will see you are stuck in state 4 and can’t escape, therefore you can’t consume the last character and be in a goal state, so the string does not match.
Now remember: any regular language has an equivalent NFA and DFA. Every regular language has a regular expression. Every NFA and DFA have a regular expression. Therefore, the DFA above must have a regular expression. Let’s build it. We want to make an equivalent to the grammar, so first we must match an a. Then we can choose between a, b, or c which in regular expressions can be expressed as (a|b|c), you’ll see why in just a bit. So our expression so far is a(a|b|c). Now we are missing one last part, the c. So we add it to the end and our expression is a(a|b|c)c. Great, this will match abc but not ac for example. The point is that this is exactly the same as the DFA above. The same left to right logic is applied.
Side note: we can write this expression more nicely as a[a-c]c .
Now that you’ve seen how regular languages, finite automata, and regular expressions are equivalent, let’s introduce the syntax of regular expressions.
Regular expressions operators
Operators act on their adjacent characters and operators. In a moment we will see that a character is also an operator. A regular expression is just a bunch of operators put together.
Now let us introduce some common operators:
Match Self Operator
The most simple operator, a character will match itself. a will match the string a. ab will match ab . Depending on your regular expression library, it may enforce whole string matches or sub string matches. In most languages/libraries substring matches are the default, so ab will also match doesn't start with ab and something following because it contains ab.
Match Any Character: .
The . means any character. It will match literally any character once.
Concatenation Operator
This operator is blank. Remember in the formal grammar introduction, two characters next to each other were concatenated, same here.
Union Operator: |
As in the formal grammar introduction, the | (pipe operator) can be thought of as an or. So a|b matches a or b but not both at the same time.
Repetition Operators
Kleene Star: *
The character * means zero to infinite amount of the preceding expression. This is essentially the same as concatenation, and is therefore also regular. For example, an expression a* will match , a, aa, aaa, and so on.
From the two operators above we can construct a very handy construct: .*
Remember, the dot means any character (a, b, c, ;, “, whatever) and the Kleene star means repeat the last expression (the dot!) infinitely, so this will match any string. Any. (ok I lied depending on your configuration or language choice, it may not match whitespaces or newlines)
One or More: +
The extension to the Kleene star: + means one or more of the preceding expression. Also regular for the same reason as above.
Zero or one: ?
The ? operator is the lazy version of +, which means it matches as little as possible to satisfy the rule. It matches zero or one of the preceding expression. For example, a? will match and a but not anything else. This is useful when you expect 1 of something or nothing such as white\s?space will match whitespace and white space but not white space (two spaces in the middle).
Intervals
{5} matches exactly 5 of the preceding expression. For example, a{5} will match aaaaa but not aaa .
{5,} matches 5 or more. {,5} matches zero to 5. {2,5} matches at least 2 but not more than 5 occurrences.
Lists
Bracket expressions are a set of items, an item being a a character class expression or a range expression. [abc] matches a or b or c. I like to think of the [] as a basket from which the expression which follows can pick anything. It is therefore possible to create constructs like [ab]+ which will match a or b one or more times, in any order.
Of course, you could also express this as (a|b)+, which we will get to in a moment. Lists have one more trick up their sleeves, which is possibly one of the most useful operators: negation. [^ab] matches any character except a or b.
Range Operator
The range operator - represents characters that fall between two characters. For example a-c will match a, b, and c. a-z matches any lower case alphabetic letter. A useful construct is [A-Z0-9] as it matches any upper case letter or number. Notice how we put two range expressions inside a list. When matching, the regex engine will look inside [] and see two expressions: A-Z and 0-9 of which either could match the input string. That’s why lists are so powerful, we could start adding more characters.
Grouping Operators
The characters ( and ) represent a capture group. Think of it as grouping the contents of the parentheses as a single unit upon which the operators act. (a) will match a and nothing else. (a|b)* matches a, aaaa, abbbb, ababa and so on. a|b* wouldn’t work, as this would be the same as (a|b*) notice how the star falls inside the parentheses, meaning a or an infinite number of bs. What makes capture groups useful is that most regex libraries will return a list of capture groups, meaning you can pick one the information you need. Super tip: you can label capture groups like so (?<name>.*) and the regular expression library will give you the string that matched the group called name. To avoid actually capturing, you can use (?:) instead of () but that’s for another time.
Escapement Operator
The \ backward slash escapes the following character. This is needed when you want to match characters that also have a meaning as an operator. For example, \( would match ( instead of throwing a syntax error (since a (normally requires a matching )). This also applies to . of course, as . will match anything (including .!) but \. will only literally match .. Note that in many implementations spaces are ignored in expressions unless they are escaped!
Anchoring
The two most useful anchors are ^ which means the start of the line (not to be confused with [^list], and $ which means the end of the line. For example, ^whole string$ will match whole string but not this is not a whole string since whole is not the very first part of the string. Conversely, whole string not won’t match either since not is between string and the end of line $. This is a useful construct when you are working with multiline strings.
Metacharacters
Confusingly reuse \, these expressions are shorthand for commonly used character classes. Here are some of the most useful.
\d one digit, this is the same as 0-9 which is the same as (0|1|2|3|4|5|6|7|8|9)
\w one word character, so it matches any letter, digit, or underscore.
\s one whitespace character: space, tab, newline, return, etc.
\D one character that is not a digit, for example A or b.
\W one character that is not a word character, such as * or -.
\S one character that is not whitespace, such as A.
\n new line character
For example, \d\d\d\d will match 2020!
Composability
An important thing to understand is that everything above can be chained together to create infinitely complex expressions. Everything can be nested. That makes regular expressions so powerful. Let’s look at a more complicated expression and break it down:
^\s*"tax_reference_number": "(?<tax_ref>\d+\.?\d+\.?\d+\.?[A-Z]\.?\d+\.?\d+)",?$
This expression gives us a capture group called tax_ref that will contain something like 123.456.789.H.123.456 or 123456789H123456. So let’s read it:
^ the string must be the start of a line.
\s* zero to infinite amount of whitespace such as spaces or tabs.
"tax_reference_number": " literally this string, exactly as it is written.
( start of a capture group
?<tax_ref> give the capture group the name tax_ref
\d+ any number one or more times.
\.? a period (escaped!) zero or once.
Rinse and repeat.
[A-Z] any upper case character in the latin alphabet.
Repeat
) the end of the capture group
" literally a quote.
,? optionally a comma, i.e. , zero or once.
$ end of line. Since we started with a ^ and ended with a $ , we ensure that it covers an entire line start to finish. This avoids matching unexpected things, like the inner contents of some different object.
Side note: this was an actual rule used to extract data out of JSON files. It only took a minute to write. It saved me an enormous amount of time.
By now I hope you can appreciate what a succinct and powerful syntax regular expressions have, and how elegantly they represent complex grammars and by extension automata. I hope that this article was useful and that even if regex is still cryptic to you, they are no longer as scary. After all, bubbly automatons are friendlier than crazy one liners, but we saw that that in the end they are the same thing. I promise you that with a little practice and some patience, you will find that regex can greatly improve your productivity. When you have a hammer, everything looks like a nail.