
Claudio Spiess
PhD Candidate, Computer Science
Bio
Hey there! I’m Claudio 👋🏼 I’m a PhD candidate in Computer Science at the University of California, Davis, affiliated with the DECAL Lab. My research interests are in the intersection of Natural Language Processing and Software Engineering. I study how machine learning techniques, mostly from the NLP world, can understand source code, and to a greater extent, help software engineering. In particular, most of my work is focused on applying LLMs (Large Language Models) to source code. I’m fortunate to be advised by Prof. Prem Devanbu, and to have collaborated with exceptional colleagues around the world. My work has been published at flagship venues such as ICSE and FSE, and I have served as a reviewer for premier journals such as TOSEM.
From model “understanding”, we can do useful things like program generation from natural language, automated bug fixing, automated documentation, anomaly detection (bugs!), reverse engineering, naming, among many others. Not only do I seek to build systems, but to investigate metaphysical questions: do LLMs understand code? What do they learn? What biases and problems do these approaches have? And most importantly, how to fix them? On the practical side, I’m interested in how cognitive load can be alleviated while writing software by smart tools for programmers. Between 2023 and 2025, my main focus was on the calibration of LLMs for code, or rather the lack thereof. In 2025, I also worked on prompt programming languages and automated prompt optimization for LLM agents. Recently, I have been working on how LLMs understand and reason about code.
Previously, I helped build a data driven lending platform at Dutch FinTech startup Floryn as a full stack software engineer, making machine learning work for loans. Most processes had some form of machine learning algorithms backing them, so I built interesting interpretation and explanation tools for non-technicals.
I received my bachelor degree in Computer Science & Engineering from the Free University of Bolzano. I wrote a research thesis, concentrating on NLP for software engineering, under the supervision of Dr. Romain Robbes and Dr. Andrea Janes. During this time, I was affiliated with the Software and Systems Engineering (SwSE) research group.
When I’m not hacking around on code or models, I like to travel the world with a backpack (44 countries/territories and counting), scuba dive (113 dives and counting), and hike volcanoes. I also speak six languages: English, German, French, Dutch, Italian, and some Spanish.
Projects
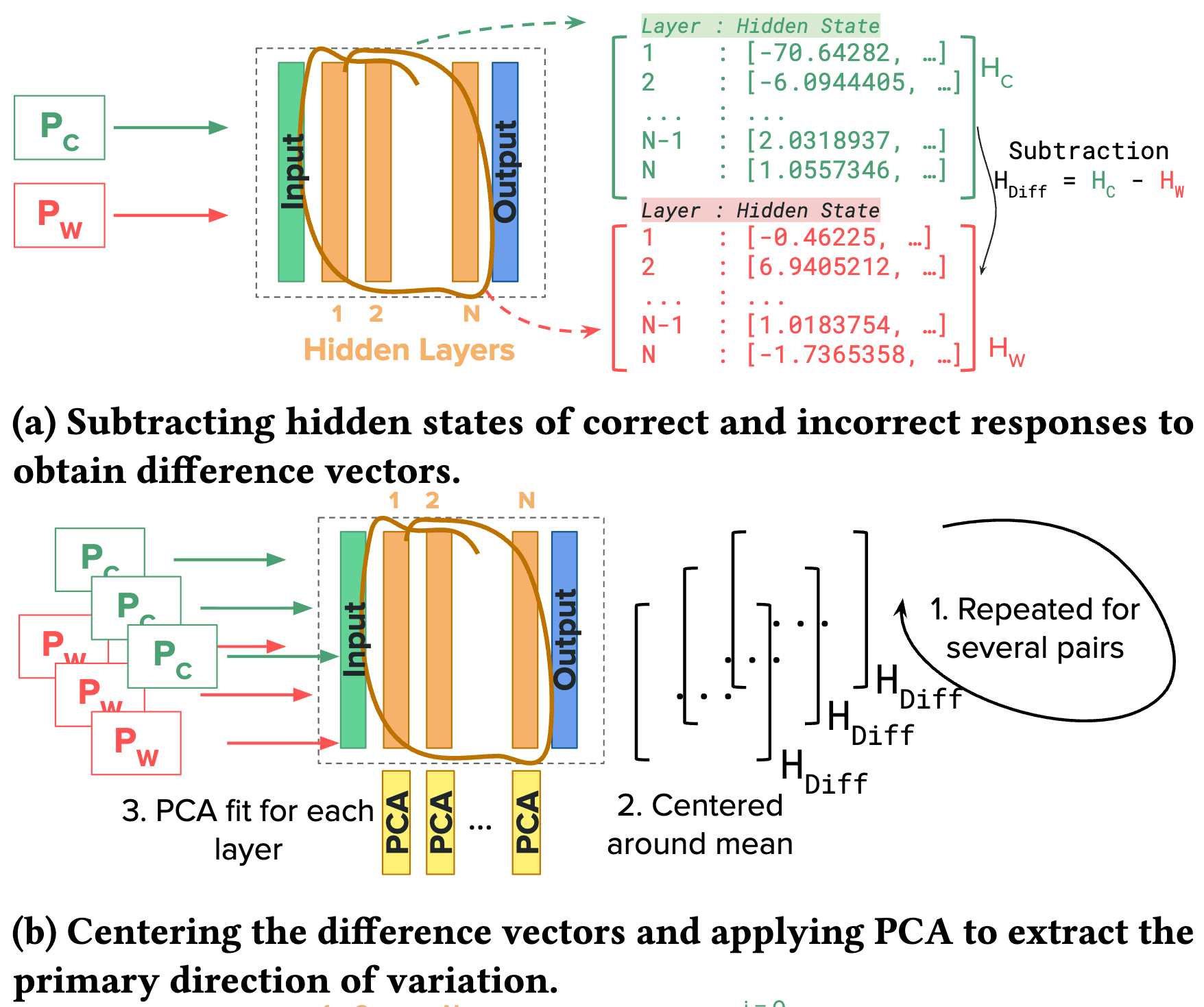
On LLMs' Internal Representation of Code Correctness
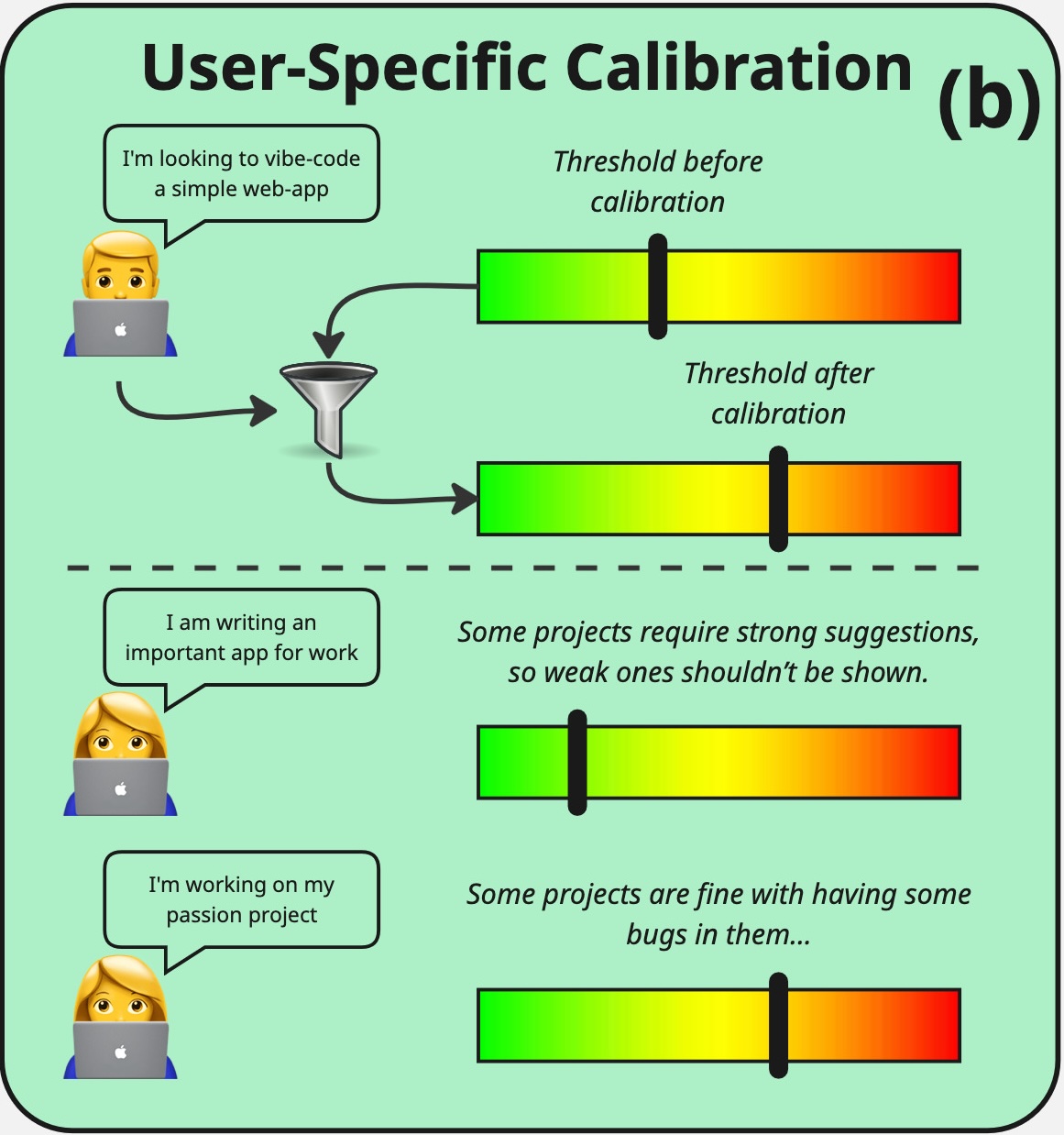
Does In-IDE Calibration of Large Language Models work at Scale?
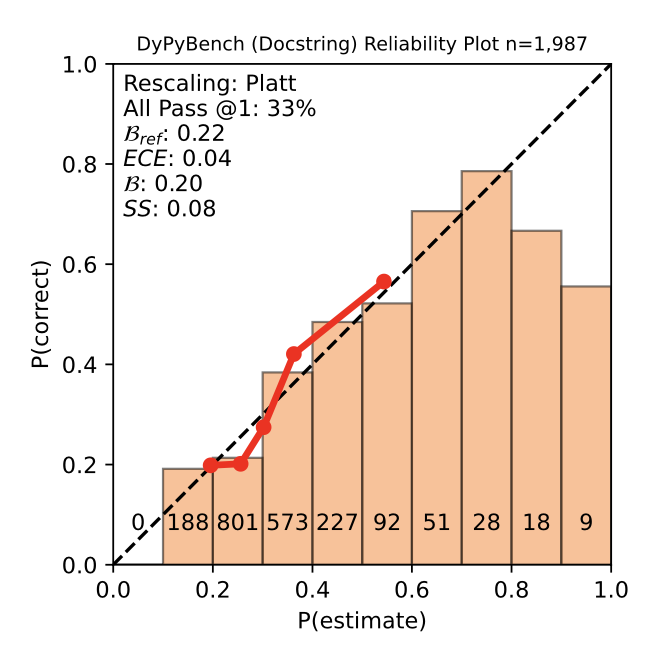
Calibration and Correctness of Language Models for Code
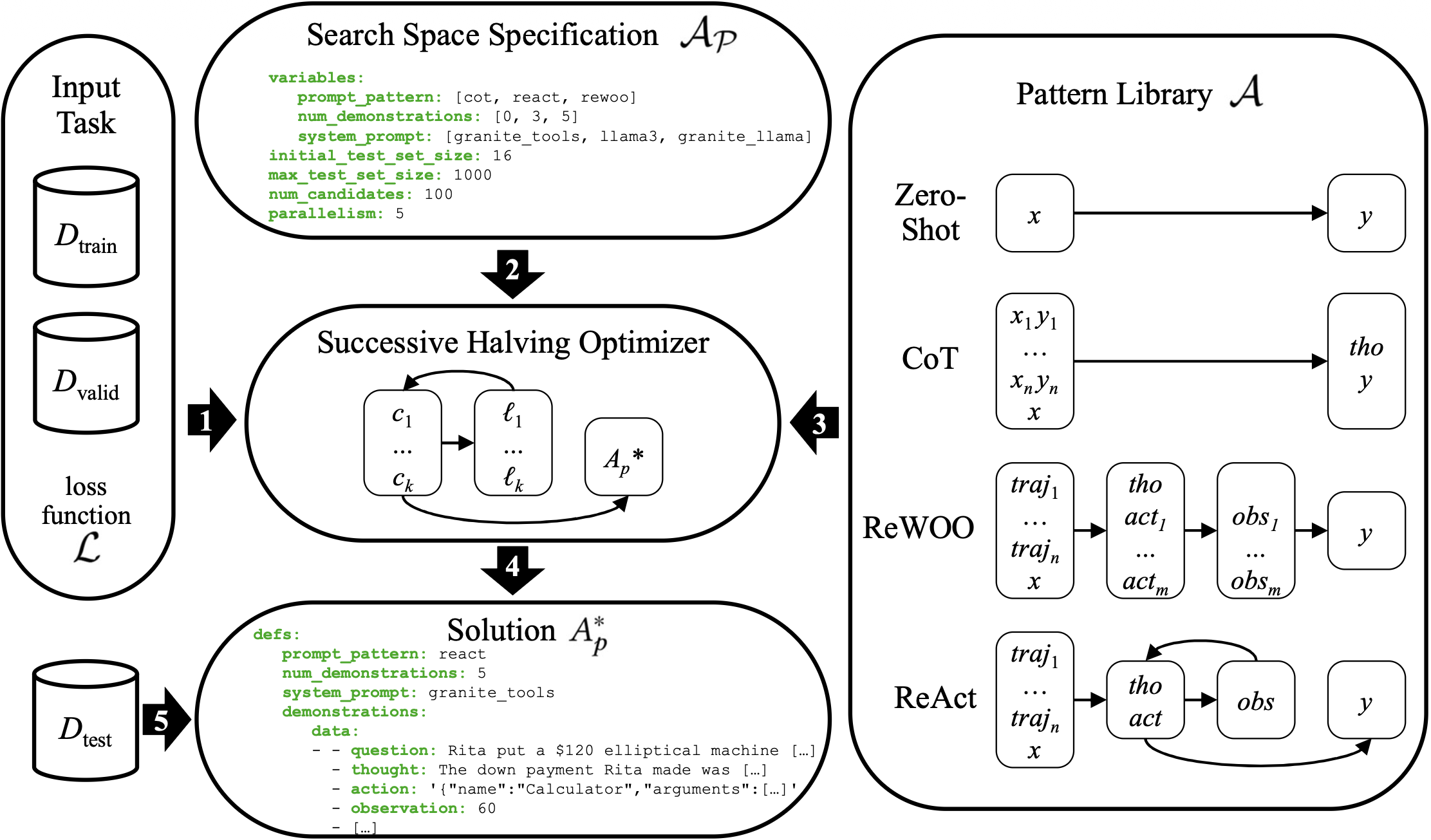
AutoPDL: Automatic Prompt Optimization for LLM Agents

PDL: A Declarative Prompt Programming Language
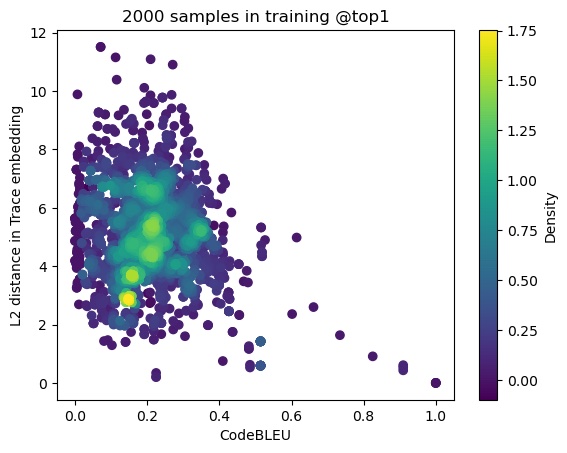
STraceBERT: Source Code Retrieval using Semantic Application Traces
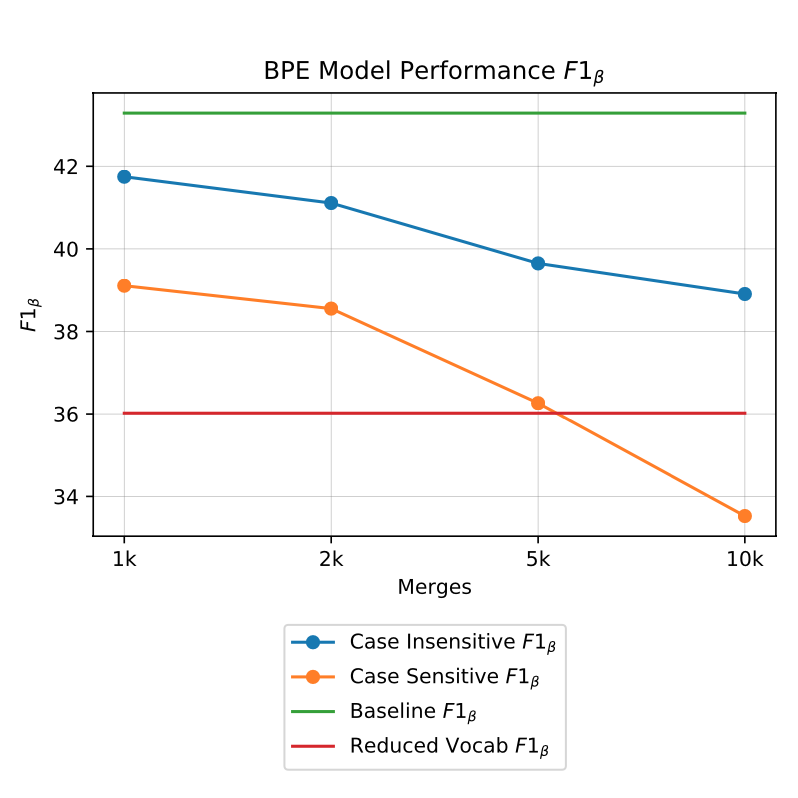
Method Name Suggestions: An Open Vocabulary Approach
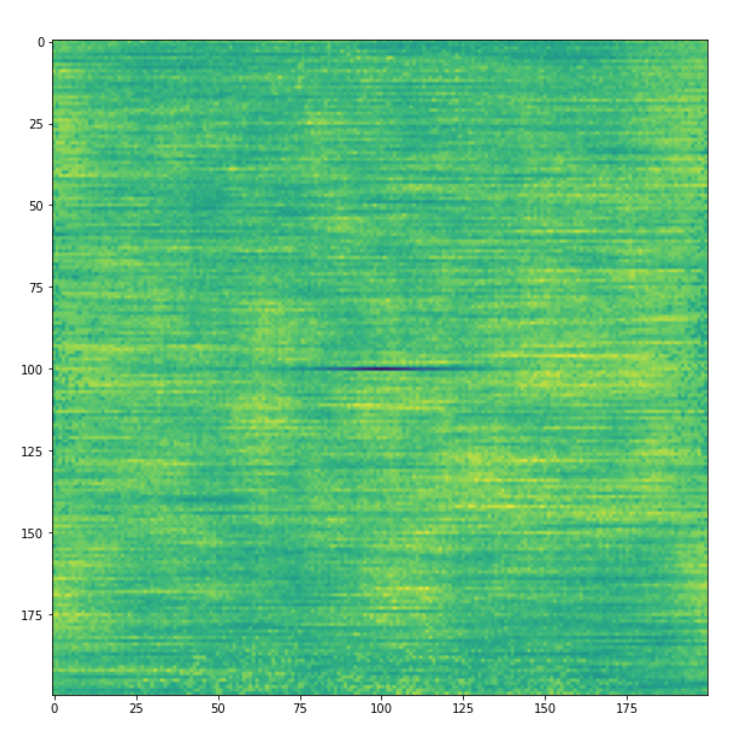
Universal Transformer: Towards Learned Positional Encodings
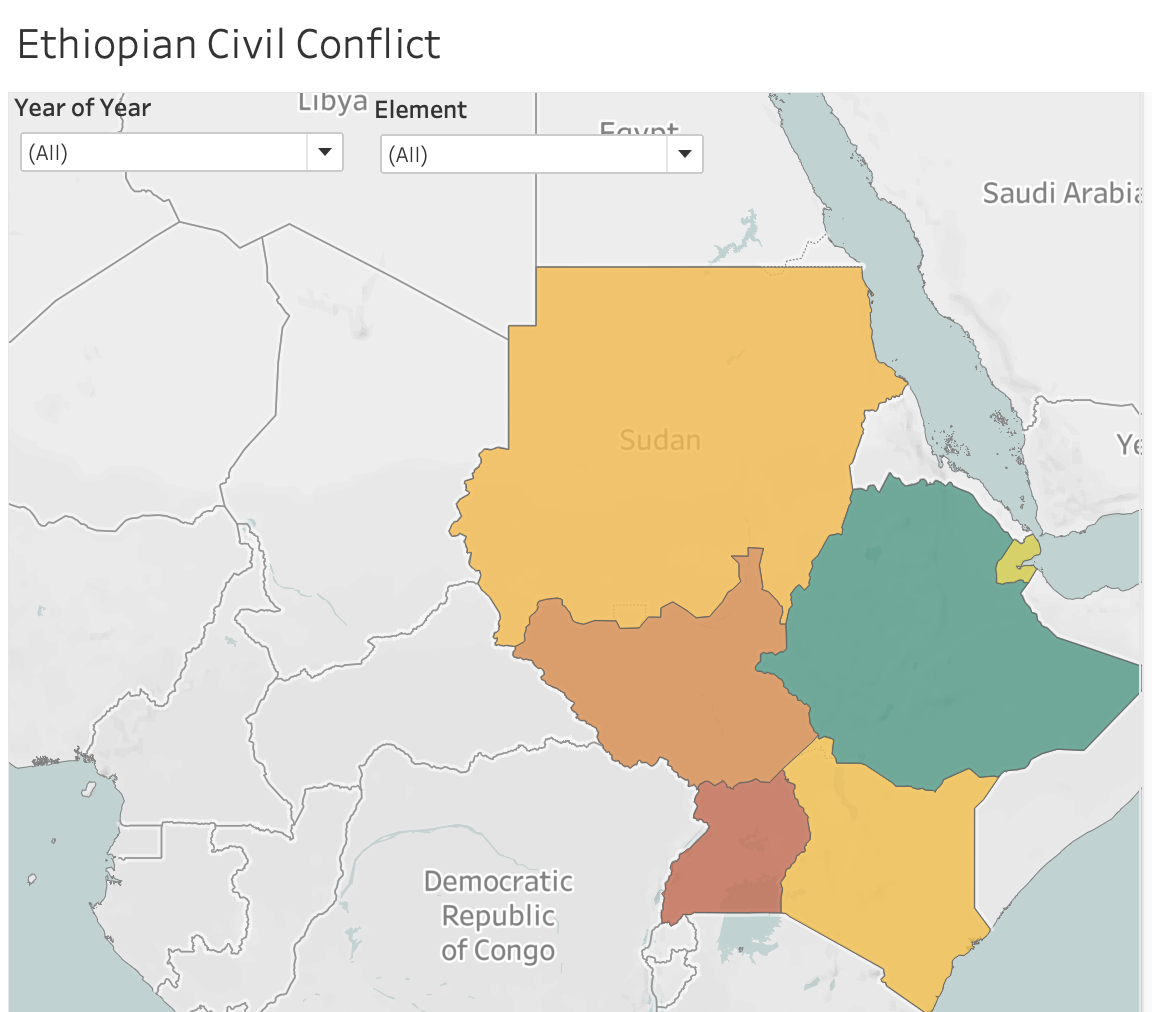
Impact of War on Food Security in the Middle East & East Africa
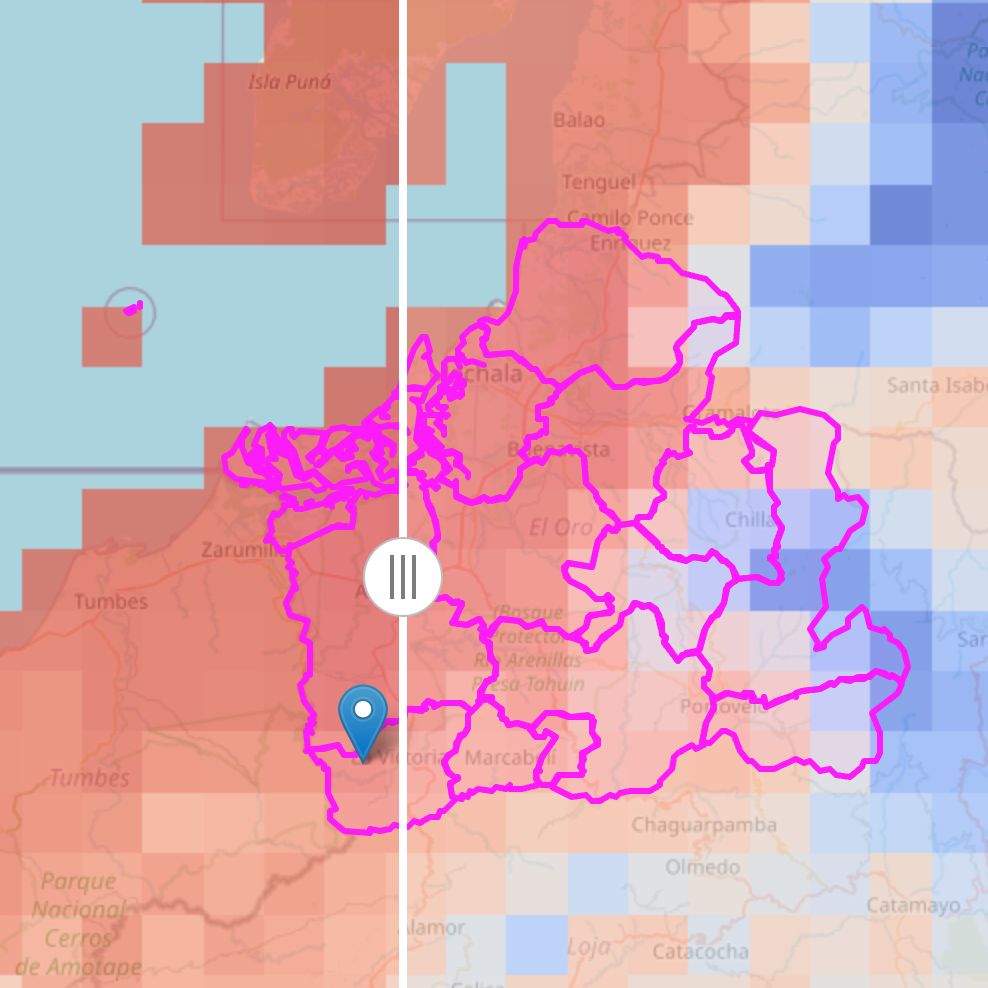
Simulating crop yields in El Oro, Ecuador
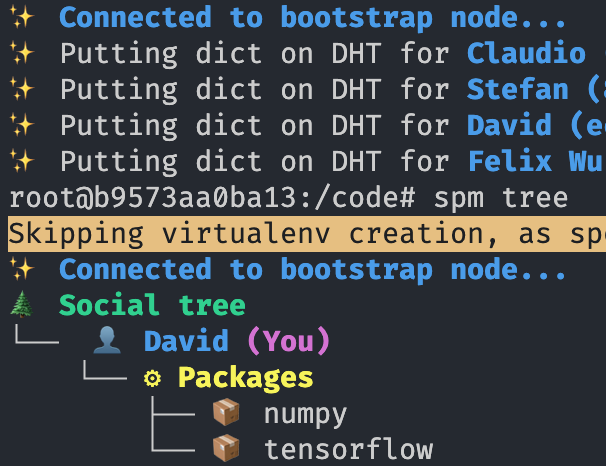
SPM: Social Package Manager
pandas-dp: Differential Privacy in pandas

CUDA Docker Stack
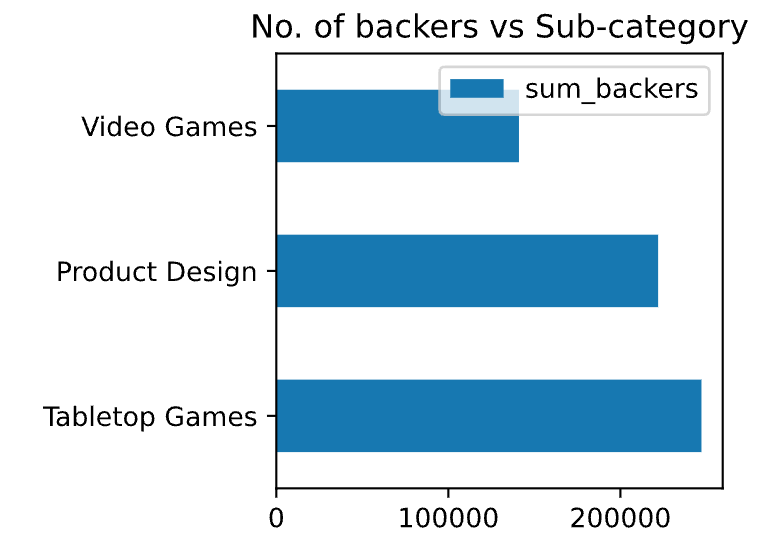
Kickstarter Project Analysis
Subtitle Keyword Extractor
PhotoStack
BBQ-Planner
DNA analysis
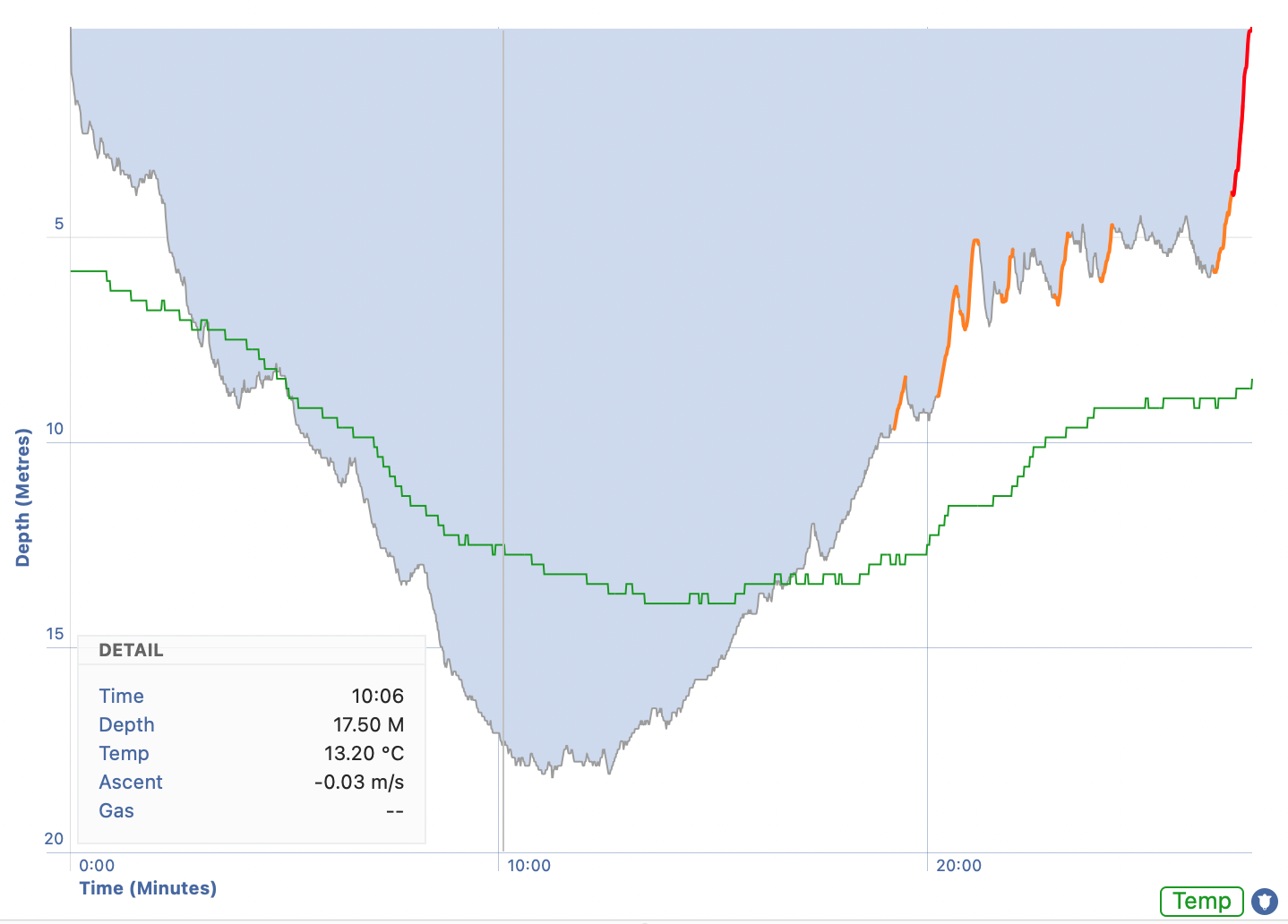
Jtrak to Macdive
ToodleMoodle
Address Book
ApiCollider
Natürliche Rechenmaschine
Network Dropbox
Cite On LLMs' Internal Representation of Code Correctness
@misc{ribeiro2026llmsinternalrepresentationcode,
title={On LLMs' Internal Representation of Code Correctness},
author={Francisco Ribeiro and Claudio Spiess and Prem Devanbu and Sarah Nadi},
year={2026},
eprint={2512.07404},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2512.07404},
}
Cite Does In-IDE Calibration of Large Language Models work at Scale?
@misc{koohestani2025doesinidecalibrationlarge,
title={Does In-IDE Calibration of Large Language Models work at Scale?},
author={Roham Koohestani and Agnia Sergeyuk and David Gros and Claudio Spiess and Sergey Titov and Prem Devanbu and Maliheh Izadi},
year={2025},
eprint={2510.22614},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2510.22614},
}
Cite Calibration and Correctness of Language Models for Code
@inproceedings{10.1109/ICSE55347.2025.00040,
author = {Spiess, Claudio and Gros, David and Pai, Kunal Suresh and Pradel, Michael and Rabin, Md Rafiqul Islam and Alipour, Amin and Jha, Susmit and Devanbu, Prem and Ahmed, Toufique},
title = {Calibration and Correctness of Language Models for Code},
year = {2025},
isbn = {9798331505691},
publisher = {IEEE Press},
url = {https://doi.org/10.1109/ICSE55347.2025.00040},
doi = {10.1109/ICSE55347.2025.00040},
abstract = {Machine learning models are widely used, but can also often be wrong. Users would benefit from a reliable indication of whether a given output from a given model should be trusted, so a rational decision can be made whether to use the output or not. For example, outputs can be associated with a confidence measure; if this confidence measure is strongly associated with likelihood of correctness, then the model is said to be well-calibrated.A well-calibrated confidence measure can serve as a basis for rational, graduated decision-making on how much review and care is needed when using generated code. Calibration has so far been studied in mostly non-generative (e.g., classification) settings, especially in software engineering. However, generated code can quite often be wrong: Given generated code, developers must decide whether to use directly, use after varying intensity of careful review, or discard model-generated code. Thus, calibration is vital in generative settings.We make several contributions. We develop a framework for evaluating the calibration of code-generating models. We consider several tasks, correctness criteria, datasets, and approaches, and find that, by and large, generative code models we test are not well-calibrated out of the box. We then show how calibration can be improved using standard methods, such as Platt scaling. Since Platt scaling relies on the prior availability of correctness data, we evaluate the applicability and generalizability of Platt scaling in software engineering, discuss settings where it has good potential for practical use, and settings where it does not. Our contributions will lead to better-calibrated decision-making in the current use of code generated by language models, and offers a framework for future research to further improve calibration methods for generative models in software engineering.},
booktitle = {Proceedings of the IEEE/ACM 47th International Conference on Software Engineering},
pages = {540–552},
numpages = {13},
keywords = {LLM, calibration, confidence measure},
location = {Ottawa, Ontario, Canada},
series = {ICSE '25}
}
Cite AutoPDL: Automatic Prompt Optimization for LLM Agents
@InProceedings{pmlr-v293-spiess25a,
title = {AutoPDL: Automatic Prompt Optimization for LLM Agents},
author = {Spiess, Claudio and Vaziri, Mandana and Mandel, Louis and Hirzel, Martin},
booktitle = {Proceedings of the Fourth International Conference on Automated Machine Learning},
pages = {13/1--20},
year = {2025},
editor = {Akoglu, Leman and Doerr, Carola and van Rijn, Jan N. and Garnett, Roman and Gardner, Jacob R.},
volume = {293},
series = {Proceedings of Machine Learning Research},
month = {08--11 Sep},
publisher = {PMLR},
pdf = {https://raw.githubusercontent.com/mlresearch/v293/main/assets/spiess25a/spiess25a.pdf},
url = {https://proceedings.mlr.press/v293/spiess25a.html},
abstract = {The performance of large language models (LLMs) depends on how they are prompted, with choices spanning both the high-level prompting pattern (e.g., Zero-Shot, CoT, ReAct, ReWOO) and the specific prompt content (instructions and few-shot demonstrations). Manually tuning this combination is tedious, error-prone, and non-transferable across LLMs or tasks. Therefore, this paper proposes AutoPDL, an automated approach to discover good LLM agent configurations. Our method frames this as a structured AutoML problem over a combinatorial space of agentic and non-agentic prompting patterns and demonstrations, using successive halving to efficiently navigate this space. We introduce a library implementing common prompting patterns using the PDL prompt programming language. AutoPDL solutions are human-readable, editable, and executable PDL programs that use this library. This approach also enables source-to-source optimization, allowing human-in-the-loop refinement and reuse. Evaluations across three tasks and six LLMs (ranging from 3B to 70B parameters) show consistent accuracy gains ($9.06 \pm 15.3$ percentage points), up to 68.9pp, and reveal that selected prompting strategies vary across models and tasks.}
}
Cite PDL: A Declarative Prompt Programming Language
@misc{vaziri2024pdldeclarativepromptprogramming,
title={PDL: A Declarative Prompt Programming Language},
author={Mandana Vaziri and Louis Mandel and Claudio Spiess and Martin Hirzel},
year={2024},
eprint={2410.19135},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2410.19135},
}
Cite STraceBERT: Source Code Retrieval using Semantic Application Traces
@inproceedings{10.1145/3611643.3617852,
author = {Spiess, Claudio},
title = {STraceBERT: Source Code Retrieval using Semantic Application Traces},
year = {2023},
isbn = {9798400703270},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3611643.3617852},
doi = {10.1145/3611643.3617852},
abstract = {Software reverse engineering is an essential task in software engineering and security, but it can be a challenging process, especially for adversarial artifacts. To address this challenge, we present STraceBERT, a novel approach that utilizes a Java dynamic analysis tool to record calls to core Java libraries, and pretrain a BERT-style model on the recorded application traces for effective method source code retrieval from a candidate set. Our experiments demonstrate the effectiveness of STraceBERT in retrieving the source code compared to existing approaches. Our proposed approach offers a promising solution to the problem of code retrieval in software reverse engineering and opens up new avenues for further research in this area.},
booktitle = {Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering},
pages = {2207–2209},
numpages = {3},
keywords = {neural information retrieval, reverse engineering, tracing},
location = {San Francisco, CA, USA},
series = {ESEC/FSE 2023}
}